
|
|
Ollamac Java Work May 2026 | |
|
|
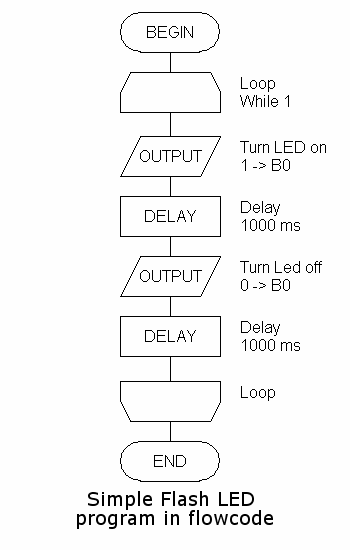
Ollamac Java Work May 2026Published by Matrix Multimedia, Flowcode is a flow chart programming language. This makes flowcode an excellent introduction into programming PIC microcontrollers. Behind the scenes the flow chart is turned into C-code which is then compiled by SourceBoost Technologies BoostC compiler. The great advantage of Flowcode is that it allows those with little experience to create complex electronic systems in minutes. Ollamac Java Work May 2026
Ollamac Java Work May 2026Integrating Ollama with Java: A Comprehensive Guide to Local AI Development The rise of Large Language Models (LLMs) has transformed how we build software, but many developers are hesitant to rely solely on cloud-based APIs like OpenAI or Anthropic due to privacy concerns, latency, and costs. Enter Ollama, the powerhouse tool that allows you to run open-source models (like Llama 3, Mistral, and Gemma) locally. For Java developers, "Ollama Java work" has become a trending focus. Integrating these local models into the Java ecosystem—leveraging the stability of the JVM with the flexibility of local AI—opens up a world of possibilities for enterprise-grade, private AI applications. Why Use Ollama with Java? Java remains the backbone of enterprise software. Integrating Ollama into your Java workflow offers several key advantages: Data Sovereignty: Sensitive data never leaves your infrastructure. This is critical for healthcare, finance, and legal sectors. Zero Latency & No Costs: You aren't paying per token, and you aren't subject to internet speeds or third-party downtime. The LangChain4j Ecosystem: The Java community has produced LangChain4j, a robust framework that makes connecting Java apps to LLMs as easy as adding a Maven dependency. Setting Up Your Environment Before writing code, you need the Ollama engine running on your machine. Download Ollama: Visit ollama.com and install it for your OS. Pull a Model: Open your terminal and run: This downloads the Llama 3 model (approx 4.7GB) to your local drive. Ollama will now host a REST API at LangChain4j is the gold standard for "Ollama Java work." It provides a declarative way to interact with models. Maven Dependency:
If you prefer not to use a framework, you can interact with Ollama’s REST API directly using Java 11+
You can build a Java application that reads your local PDF documentation, stores embeddings in a local vector database (like Chroma or Milvus), and uses Ollama to answer questions based only on your private files. Intelligent Unit Test Generation Java developers are using Ollama to build custom CLI tools that scan their Using the "JSON mode" in Ollama, you can pass messy, unstructured logs from a Java Spring Boot application and have the model return a clean, structured JSON object for analysis. Performance Considerations Running LLMs locally requires hardware resources. When working with Java and Ollama: RAM: 8GB is the minimum for 7B models; 16GB-32GB is recommended. GPU: While Ollama runs on CPU, having an Apple M-series chip or an NVIDIA GPU will significantly speed up "tokens per second." Context Window: Be mindful of the context size in your Java code. Passing too much text (like an entire library of code) can lead to slow response times or memory errors. Conclusion The intersection of Ollama and Java represents a shift toward "Small AI"—efficient, local, and highly specialized. Whether you are building an AI-powered IDE plugin, a private corporate chatbot, or an automated code reviewer, the combination of Ollama's model management and Java's robust ecosystem provides a production-ready foundation. By mastering these integrations today, you ensure your Java applications remain relevant in an AI-driven future without compromising on privacy or cost. This report outlines the integration and workflow for using environments, covering local setup, core libraries, and framework-specific implementations. 1. Executive Summary: Ollama in Java Integrating Ollama with Java: A Comprehensive Guide to Ollama serves as a local inference server that allows Java developers to run large language models (LLMs) like Llama 3, Mistral, and DeepSeek without cloud dependencies. For Java work, this enables data privacy, zero API costs, and offline capabilities for AI-powered applications. 2. Core Setup & Infrastructure To begin Java development with Ollama, the local server must be active: Installation : Download and install Ollama for macOS, Linux, or Windows Local Server : By default, the server runs on Introduction: The Shift Toward Private, On-Premise AIFor the past two years, the software engineering world has been obsessed with cloud-based large language models (LLMs) like GPT-4, Claude, and Gemini. However, a quiet revolution is taking place in enterprise Java departments. Concerns over data privacy, latency, and API costs are driving developers to run LLMs locally. Enter Ollama – the tool that makes running models like Llama 3, Mistral, and Phi-3 as easy as The answer lies in understanding OllamaC Java work – a term that encapsulates the integration of Ollama’s HTTP API with Java clients, the emerging community around C-bindings (OllamaC), and the practical workflows for building robust, local AI features in Java. This article will walk you through everything you need to know about OllamaC Java work: from basic setup to advanced streaming, function calling, and performance tuning. 4.3 Model HandlingCaches model metadata to reduce Or download from ollama.com for Windows (WSL2 recommended)7. ConclusionFor Java developers targeting low-latency, privacy-conscious applications, Ollama provides a compelling option to run language models locally on Apple M1 hardware. With careful model selection, async integration patterns, and resource management, Java applications can harness on-device inference effectively, reducing dependency on cloud services while maintaining enterprise-grade behavior. Would you like this expanded into a longer essay, include code samples (Java + HTTP streaming), or tailor it to a specific Java framework? When working with Ollama in Java, you can leverage several key features through libraries like Spring AI and Ollama4j. These features allow you to integrate local Large Language Models (LLMs) directly into your Java ecosystem. Core AI Capabilities Chat and Generation: Perform single-turn text generation or multi-turn chat with full conversation history management. Streaming Responses: Stream AI responses in real-time using Server-Sent Events (SSE) or callbacks, which is critical for building responsive chatbot UIs. direct C bindings for performance Function and Tool Calling: Register standard Java methods as "tools" that the model can choose to call. The library handles the automatic conversion of Java methods into JSON schemas for the model. Reasoning/Thinking Mode: Support for specialized models like DeepSeek-R1 that can output their internal reasoning process before providing a final answer. Multimodality: Send images alongside text prompts for models that support vision (e.g., LLaVA). Enterprise and Infrastructure Features Spring AI with Ollama Tool Support Integrating Ollama with Java is a major shift for developers, as it brings the power of Large Language Models (LLMs) like Llama 3, Mistral, and DeepSeek-R1 directly into local environments. By using Java-based frameworks, you can build private, cloud-free AI applications without relying on expensive external APIs or internet connectivity. Core Integration Strategies Java developers typically use one of three main paths to connect with Ollama: Function to load model on Spring Ollama · Issue #526 - GitHub Based on the prompt "ollamac java work," I have interpreted this as a request for an essay discussing the technical integration, implementation, and significance of using Ollama (a tool for running large language models locally) with the Java programming language. Here is an essay exploring that topic. Part 8: Future of OllamaC in the Java EcosystemThe Java community is actively working on better integration:
We can expect a native For now, mastering OllamaC Java work means being able to choose the right abstraction: HTTP for simplicity, direct C bindings for performance, and high-level frameworks for rapid development. |
|
Copyright © 2008 SourceBoost Technologies
| |